"NLP와 LLM 실전 가이드"는 자연어 처리(Natural Language Processing)라는 거대한 기술 분야를, 이론적 엄밀성과 실무 지향성을 모두 갖춘 구조로 안내하는 보기 드문 책이다. 이 책은 단순한 ‘개론서’가 아니다. 머신러닝과 수학, 통계 기초부터 시작해, GPT-3 및 LangChain 기반의 고급 응용에 이르기까지 하나의 통합된 흐름으로 연결되어 있다. 특히 최근 화두인 RAG(Retrieval-Augmented Generation), 프롬프트 엔지니어링, LLM 파인튜닝 등 최신 기술들을 실용적 코드 예제와 함께 상세히 다루는 점이 인상적이다.
? 기초: 머신러닝과 수학, 통계의 탄탄한 바탕
초반부(1~3장)는 자연어 처리에 대한 철학적 접근과 함께, 이를 수학적으로 설명할 수 있는 기초 체계를 다진다. 선형대수(벡터, 행렬, 고유값/고유벡터), 확률 이론(조건부 확률, 베이즈 정리), 통계 개념(기대값, 분산, 상관 계수) 등은 단순한 수식 나열이 아닌, NLP 알고리즘이 어떻게 이 수학 개념을 활용하는지까지 설명한다.
예를 들어, Word2Vec 임베딩이 의미 공간을 벡터로 표현할 때 코사인 유사도를 사용하는 수학적 배경이나, Naive Bayes 분류기가 문장 내 단어 출현 빈도를 확률 분포로 해석하는 방식 등을 상세하게 다룬다. 이론 뒤에는 항상 파이썬 실습 예제가 따라오므로, 학습자 입장에서도 추상적 개념을 직접 구현해볼 수 있다.
⚙️ 전통적인 NLP 파이프라인의 구성과 실전 전략
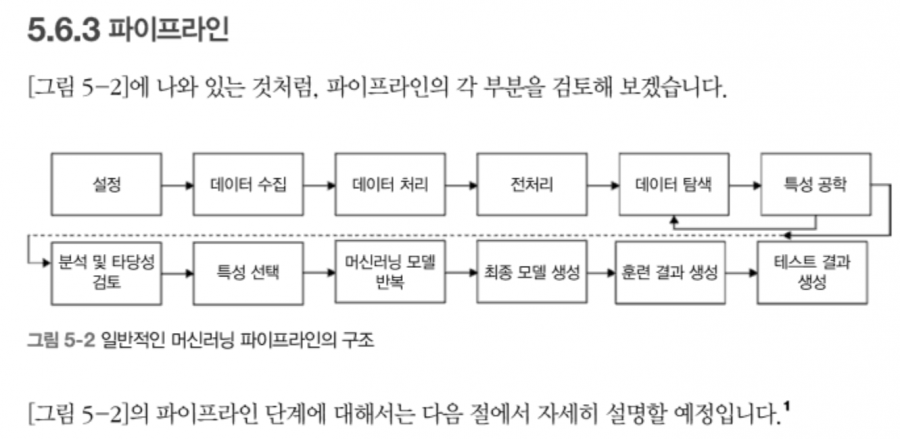
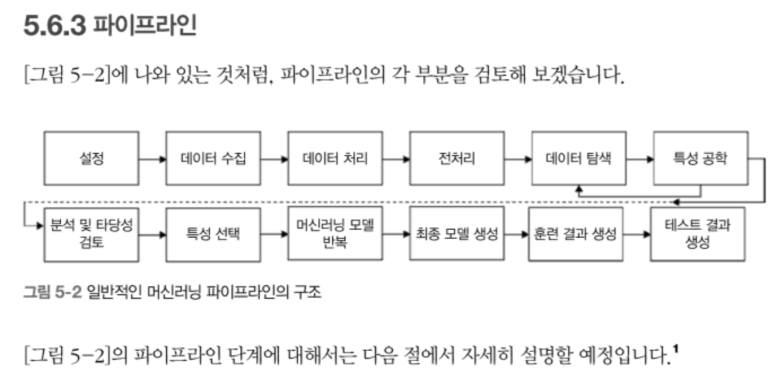
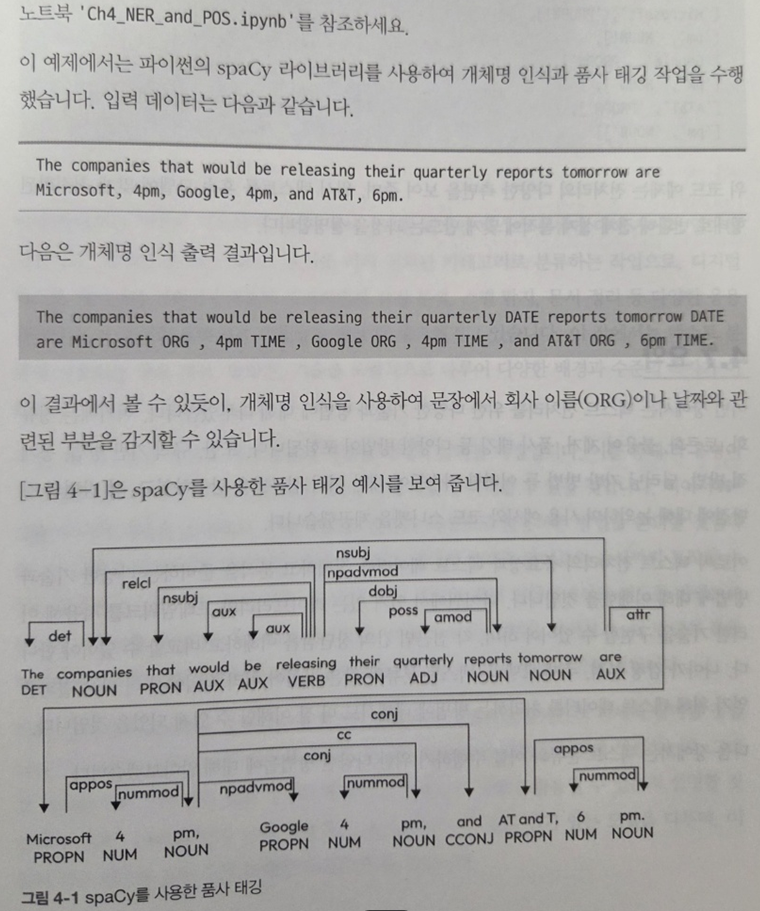
중반부(4~5장)에서는 실제 자연어 처리 파이프라인을 어떻게 구성할 수 있는지 단계별로 다룬다. 텍스트 정규화, 토크나이징, 품사 태깅, 개체명 인식(NER), 불용어 제거 등의 전처리 작업은 모두 Scikit-learn, spaCy, NLTK 등 널리 쓰이는 라이브러리를 활용해 설명된다.
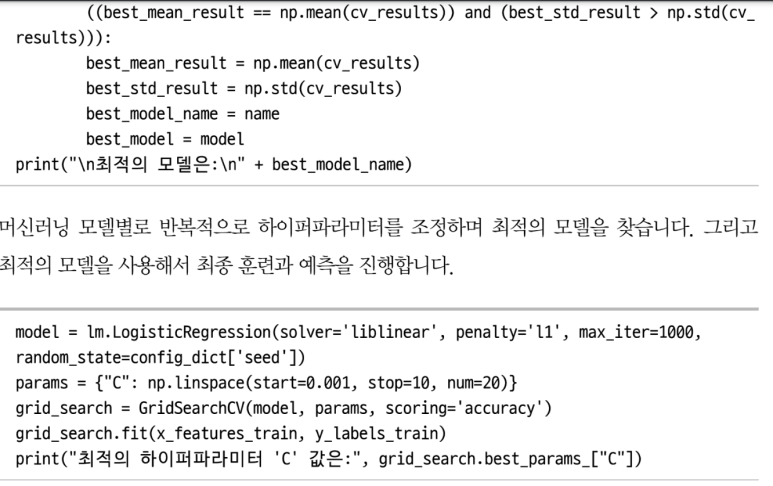
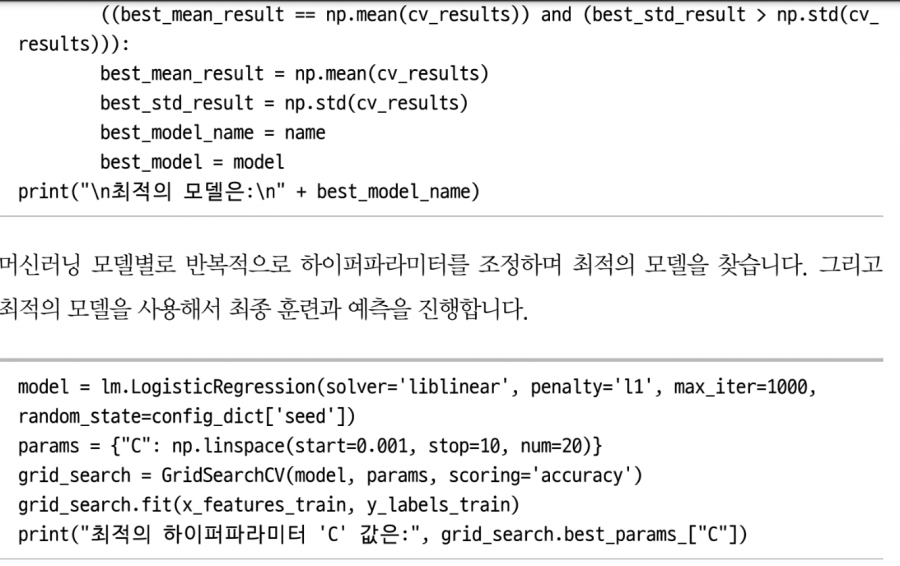
TF-IDF와 Word2Vec을 기반으로 한 전통적인 텍스트 분류 모델들을 소개하며, Logistic Regression, Random Forest, SVM 등 머신러닝 기법들이 NLP에서 어떻게 사용되는지 보여준다. 이때 단순한 분류 정확도(accuracy)만 보는 것이 아니라, Precision, Recall, F1 Score, ROC Curve와 같은 실제 현업에서 쓰이는 정량적 평가 지표를 함께 설명하여, 실무와의 연결 고리를 놓치지 않는다.
? LLM의 구조, 트랜스포머 메커니즘, GPT 모델까지
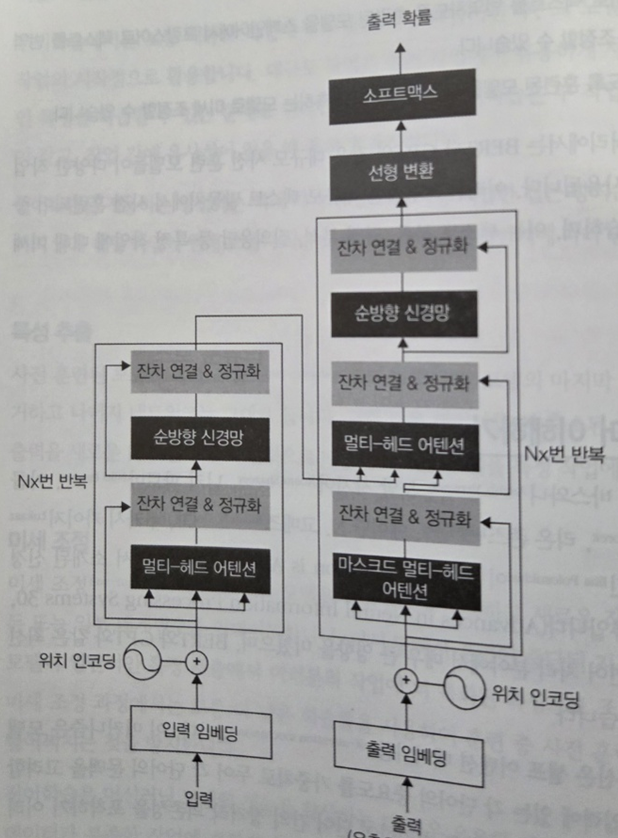
6장 이후부터는 본격적으로 딥러닝 기반 NLP, 특히 트랜스포머(Transformer) 아키텍처와 대규모 언어 모델(LLM, Large Language Model)에 대한 논의가 시작된다. Positional Encoding, Self-Attention, Multi-head Attention, Residual Connection 등 트랜스포머의 핵심 요소들을 수식과 함께 시각적 다이어그램으로 설명한다.
특히 GPT-2/3 같은 오토리그레시브 모델과 BERT 같은 양방향 모델의 구조적 차이와 학습 방식 차이를 비교해 설명해주는 부분은 매우 유익하다. GPT-3의 파라미터 수가 175B(십칠십오억 개)에 달하는 이유, 그리고 그로 인한 메모리·컴퓨팅 자원의 제약, 프롬프트 기반 제로샷/원샷/퓨샷 학습 전략 등은 최근 NLP 산업 현장의 고민과 그대로 맞닿아 있다.
? RAG, LangChain, 프롬프트 최적화 등 실무 중심의 고급 응용
8~9장에서는 GPT와 같은 LLM을 단순히 호출하는 수준을 넘어서, 이를 외부 지식베이스와 결합하여 정답률을 높이는 RAG 구조(Retrieval-Augmented Generation), 그리고 LangChain을 사용한 프롬프트 체인 구성 방법 등 실무에 바로 적용할 수 있는 고급 기법들이 등장한다.
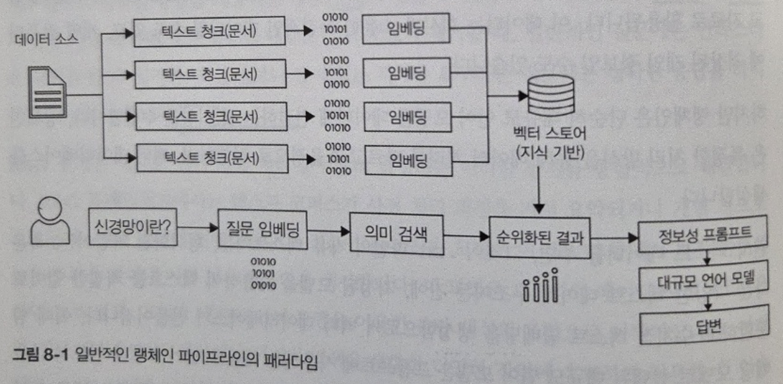
예를 들어, 문서 검색 → 임베딩 → 벡터DB(예: FAISS, Chroma) → LLM 질의 응답 흐름을 설계하는 방법, 로컬 LLM(OpenLLaMA, Mistral 등) 운영 전략, 클라우드 상의 API 호출 비용 절감 방안(Prompt Compression, Token Truncation 등)까지 구체적으로 다뤄진다.
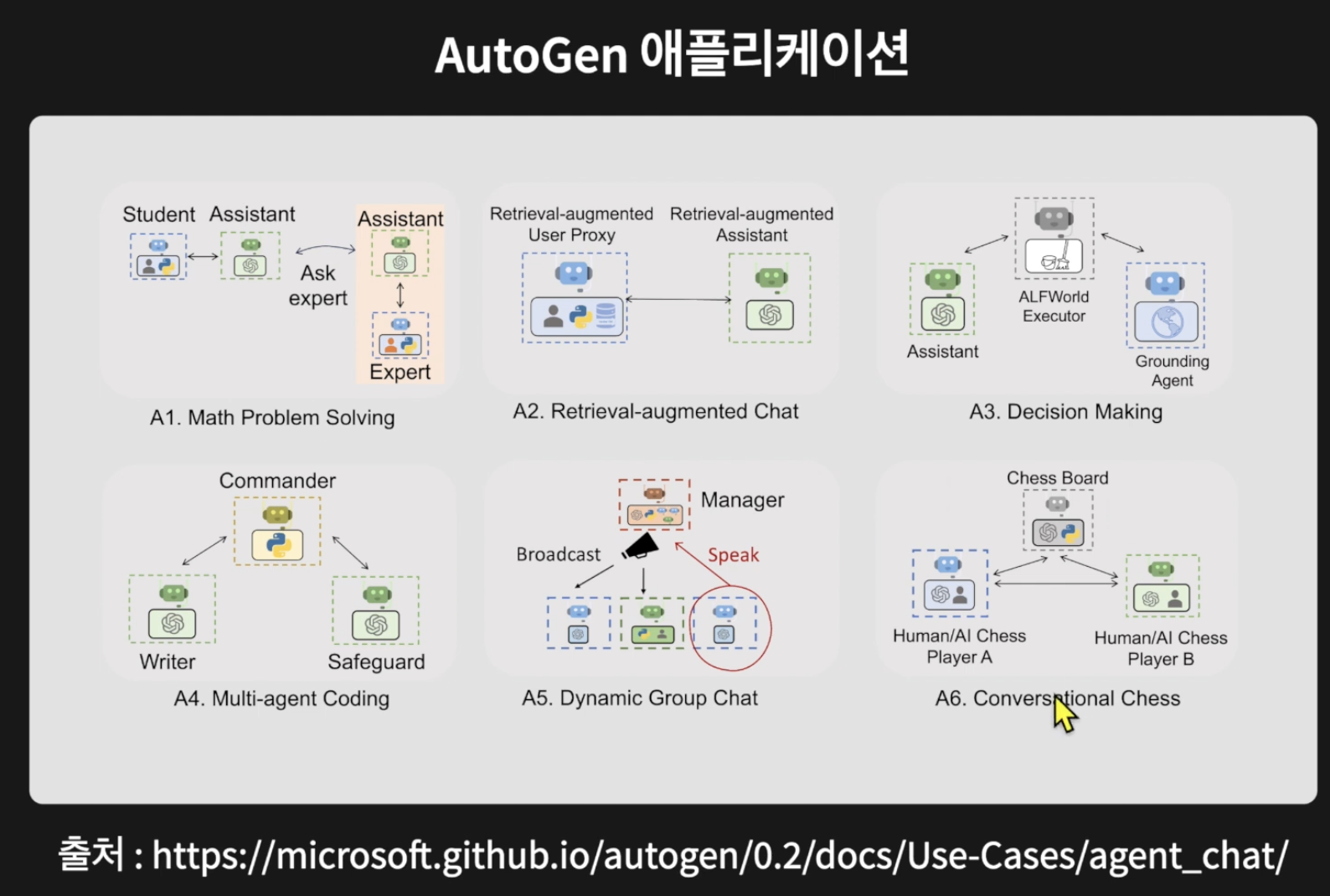
멀티 에이전트 기반 LLM 시스템 설계와 같은 최근 연구 트렌드도 간략히 소개되어, 최신 동향을 이해하는 데도 도움이 된다.
? 트렌드, 산업 전망, 그리고 전문가 인터뷰
마지막 10~11장은 NLP와 LLM 기술이 산업, 사회, 윤리 등에 미치는 영향을 분석하고 있다. 대규모 언어 모델이 단순한 챗봇 이상의 존재가 되어가는 현상, 기업 내 데이터 자산을 LLM과 접목해 검색·분석 능력을 자동화하는 현장 사례들이 흥미롭게 다가온다. 또한 실제 업계 전문가들과의 인터뷰도 포함되어 있어 독자가 기술을 넘어서 실무와 조직, 비즈니스 전략까지 통합적으로 생각할 수 있게 돕는다.
이 도서는 이론적으로 탄탄하고 실습적으로 충실하며, 무엇보다 산업 응용과 트렌드에 민감하게 반응한다. 자연어 처리라는 기술이 단순한 분류 문제를 넘어, 산업을 바꾸고 인간의 사고를 재구성하는 도구로 진화하고 있는 지금, 이 책은 기술 리더로서 NLP, LLM을 학습하는데 충분한 기술적 깊이를 전달한다.
"한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다."