책소개
데이터 분석에서 시각화까지 패키지로 배우는 실무형 R 입문서
데이터 분석가는 단순히 R 언어를 아는 것을 넘어 업계에서 표준처럼 쓰이는 각종 패키지에도 능통해야 한다. 다양한 기능을 GUI로 제공하는 R스튜디오 사용법을 익히는 것도 중요하고, 클라우드에 분석 환경을 구축하고 웹 앱을 만드는 법도 알아야 한다. 이 책은 실무에서 많이 사용하는 R스튜디오 기능과 각종 패키지 중심으로 R을 학습할 수 있게 쓰였다. 실무 친화적으로 데이터 분석과 시각화 기법을 소개하고, AWS 등 클라우드 환경과의 연동 방법도 설명한다.
저자소개

목차
PART 1 데이터 과학과 R 언어
CHAPTER 1 데이터 과학으로 가는 길
1.1 데이터 과학의 길
__1.1.1 데이터로 하는 일은?
__1.1.2 데이터와 관련된 직업은?
__1.1.3 데이터 과학자에게 필요한 역량은?
__1.1.4 데이터 과학자가 되려면?
1.2 데이터 과학 기술 트렌드
__1.2.1 데이터 분석 언어
__1.2.2 데이터 분석 기술
__1.2.3 데이터 시각화 기술
CHAPTER 2 데이터 월드 경험하기
2.1 R, MRO, R스튜디오 설치하기
__2.1.1 R 설치하기
__2.1.2 MRO 설치하기
__2.1.3 R스튜디오 설치하기
2.2 R스튜디오 살펴보기
__2.2.1 기본 레이아웃
__2.2.2 새 프로젝트 만들기
__2.2.3 프로젝트 저장
__2.2.4 R스튜디오와 R 연동하기
PART 2 R 기본 배우기
CHAPTER 3 데이터 형태와 구조
3.1 데이터 형태
__3.1.1 특수한 상태를 나타내는 상수
__3.1.2 논릿값(진릿값)
__3.1.3 범주형
__3.1.4 문자형
__3.1.5 숫자형
__3.1.6 데이터 타입 확인
3.2 데이터 구조
__3.2.1 벡터
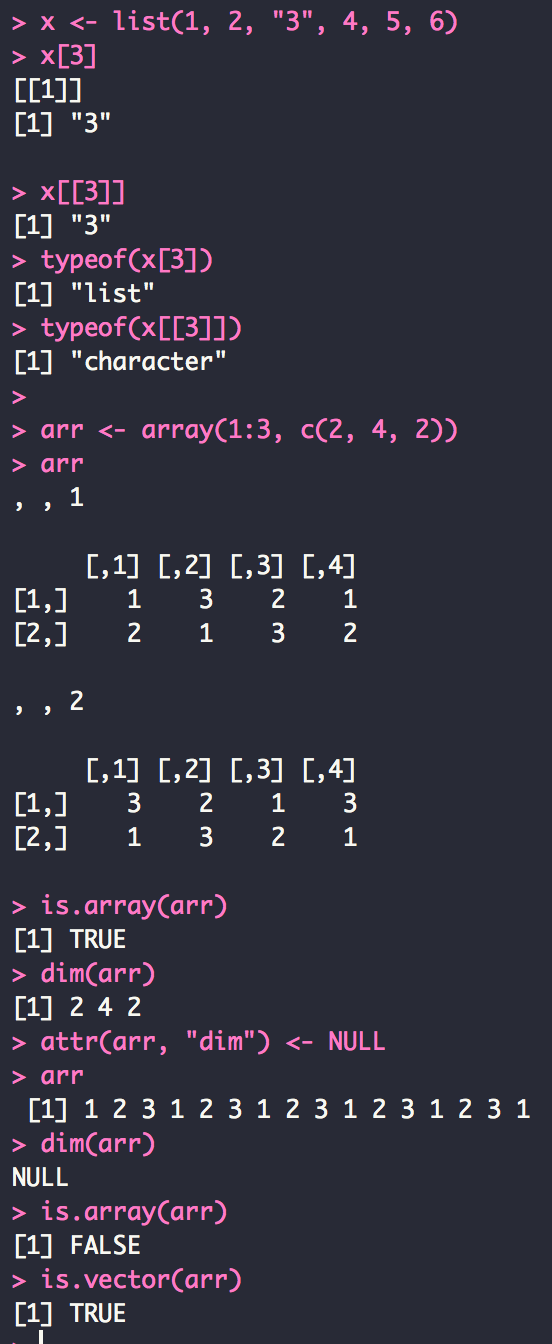
__3.2.2 리스트
__3.2.3 배열과 행렬
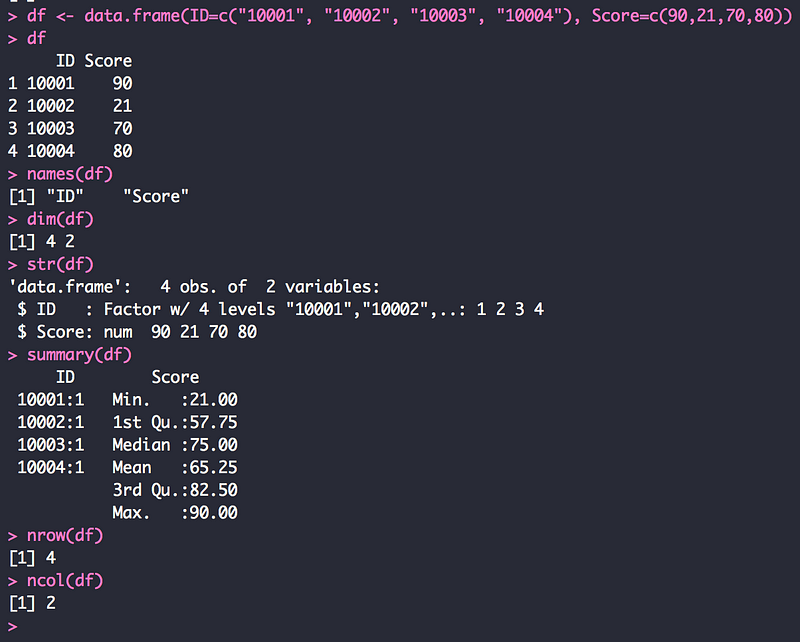
__3.2.4 데이터 프레임
3.3 연산자
__3.3.1 할당 연산자
__3.3.2 산술 연산자
__3.3.3 관계 연산자
__3.3.4 논리 연산자
3.4 함수와 변수
__3.4.1 함수
__3.4.2 기술통계 함수
__3.4.3 전역변수, 지역변수, 매개변수
3.5 제어문(조건문)
__3.5.1 if문
__3.5.2 switch문
__3.5.3 for문
__3.5.4 while문
CHAPTER 4 데이터 핸들링
4.1 dplyr와 tidyr 치트시트
4.2 데이터 핸들링 기초
__4.2.1 tbl_df()
__4.2.2 glimpse()
__4.2.3 %>% ( 파이프)
4.3 데이터 열/행 조작
__4.3.1 gather()
__4.3.2 spread()
__4.3.3 separate()
__4.3.4 unite()
4.4 필요한 행만 선택하기
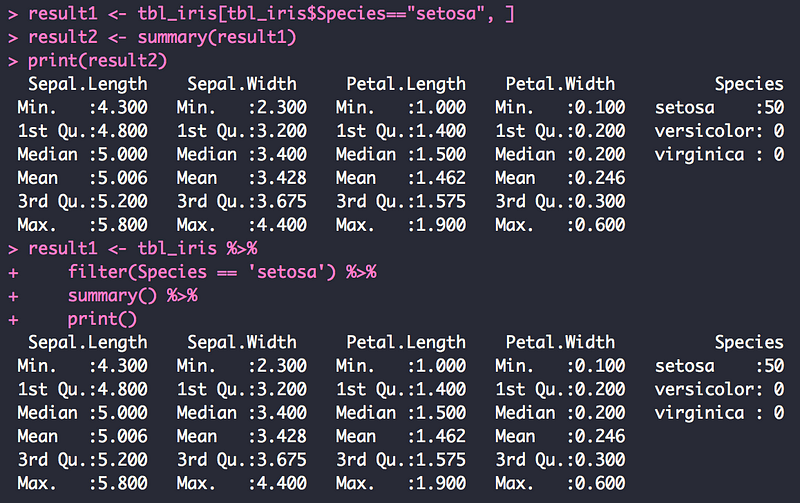
__4.4.1 filter()
__4.4.2 slice()
4.5 필요한 열만 선택하기
__4.5.1 select()
4.6 데이터 조합하기(열 기준)
__4.6.1 bind_cols()
__4.6.2 left_join()
__4.6.3 right_join()
__4.6.4 inner_join()
__4.6.5 full_join()
4.7 데이터 조합하기(행 기준)
__4.7.1 bind_rows()
__4.7.2 intersect()
__4.7.3 setdiff()
__4.7.4 union()
4.8 파생 데이터 만들기
__4.8.1 mutate()
__4.8.2 transmute()
PART 3 데이터 분석하기
CHAPTER 5 데이터 가져오기
5.1 CSV, XLS, TXT: 공공데이터포털
__5.1.1 CSV 데이터
__5.1.2 엑셀 데이터
__5.1.3 TXT 데이터
5.2 XML과 JSON: 서울열린데이터광장
__5.2.1 XML 데이터
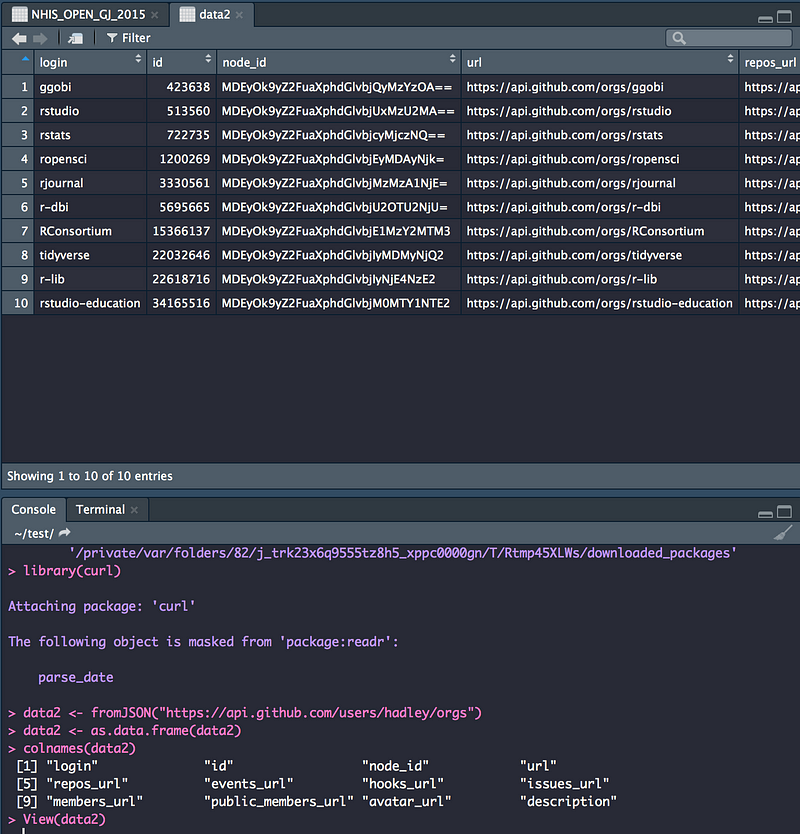
__5.2.2 JSON 데이터
5.3 데이터베이스
__5.3.1 MS SQL 서버
__5.3.2 MySQL
__5.3.3 dbplyr와 pool 패키지
5.4 R 내장 데이터셋
5.5 빅데이터(feather와 fst)
CHAPTER 6 통계분석 기초
6.1 통계분석 기법
__6.1.1 요약통계
__6.1.2 가설검정: 귀무가설, 대립가설, p 값
__6.1.3 평균과 표준편차
__6.1.4 빈도 분석
__6.1.5 분위수와 사분위수
6.2 정규분포와 정규성 검정
__6.2.1 표준정규분포 곡선
__6.2.2 샤피로-윌크 검정
6.3 데이터 검정
__6.3.1 카이제곱검정
__6.3.2 t 검정
__6.3.3 분산분석
CHAPTER 7 고급 데이터 분석 기법
7.1 상관분석
7.2 회귀분석
__7.2.1 다양한 회귀분석 방법
__7.2.2 다중회귀분석 실습
7.3 의사결정나무
__7.3.1 의사결정나무 개요
__7.3.2 의사결정나무 R 함수
__7.3.3 의사결정나무 실습
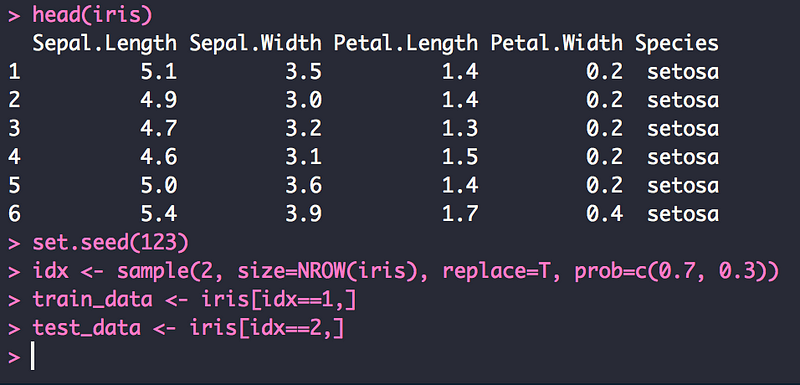
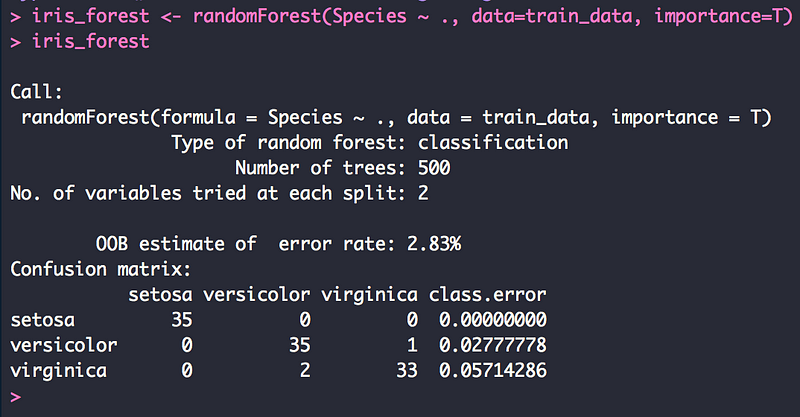
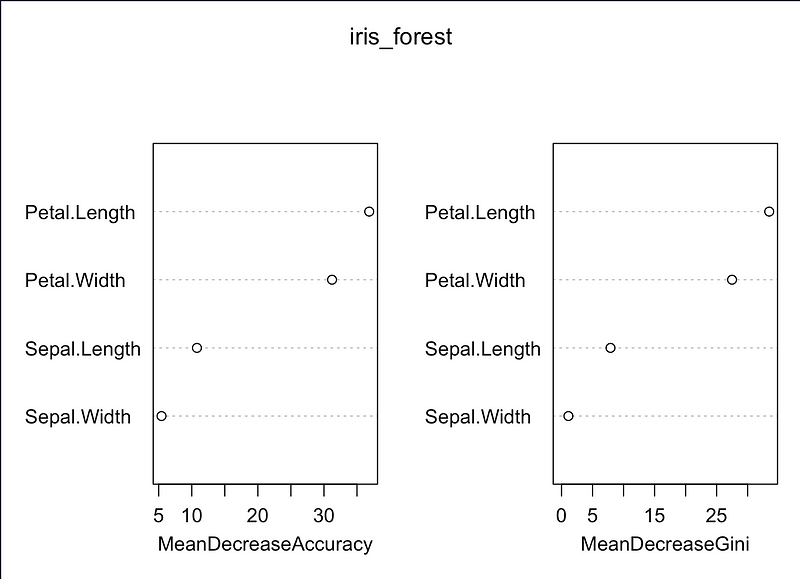
7.4 랜덤 포레스트
CHAPTER 8 데이터 시각화
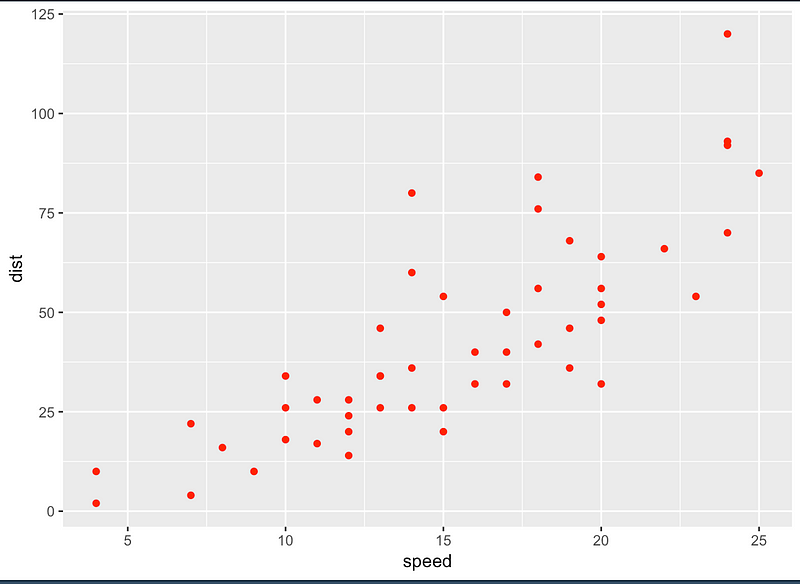
8.1 ggplot2 패키지
__8.1.1 ggplot2 패키지 설치
__8.1.2 소품문 및 참고 자료
8.2 ggplot2 구성 요소와 문법 구조
__8.2.1 메타데이터 생성
__8.2.2 레이어 상속
__8.2.3 colour 매핑과 group 매핑
__8.2.4 기하 객체와 통계 객체
__8.2.5 기하 객체와 통계 객체의 결합
8.3 ggplot2 치트시트
__8.3.1 변수가 하나일 때
__8.3.2 변수가 두 개일 때
8.4 ggThemeAssist 패키지
__8.4.1 ggThemeAssist 패키지 설치
__8.4.2 Settings
__8.4.3 Panel & Background
__8.4.4 Axis
__8.4.5 Title and label
__8.4.6 Legend
__8.4.7 Subtitle and Caption
8.5 ggplot2와 ggThemeAssist 함께 활용하기
PART 4 클라우드를 이용한 데이터 분석
CHAPTER 9 클라우드 분석 환경 구성
9.1 아마존 웹 서비스
__9.1.1 아마존 웹 서비스 가입하기
__9.1.2 리눅스+R+R스튜디오 구성
__9.1.3 웹으로 R스튜디오 접속하기
__9.1.4 요금표
9.2 애저
__9.2.1 애저 가입하기
__9.2.2 리눅스+R+R스튜디오 구성
__9.2.3 웹으로 R스튜디오 접속하기
__9.2.4 요금표
CHAPTER 10 클라우드 분석 활용하기
10.1 AWS 클라우드로 분석하기
__10.1.1 인스턴스 구성
__10.1.2 R스튜디오 컴파일 설정 및 새 프로젝트
__10.1.3 HTML 컴파일 및 접속
__10.1.4 의사결정나무 R 마크다운 버전
10.2 R 마크다운으로 데이터 연동형 보고서 작성하기
__10.2.1 R 마크다운 치트시트
__10.2.2 R 마크다운 기초
__10.2.3 청크 옵션
__10.2.4 라벨
__10.2.5 기타 청크 옵션
10.3 shiny로 반응형 분석 앱 개발하기
__10.3.1 shiny 웹 앱 생성
__10.3.2 랜덤 포레스트 분석 앱
__10.3.3 의사결정나무 분석 앱
10.4 shiny와 플로틀리로 반응형 시각화 강화하기
출판사리뷰
R스튜디오에서 클라우드까지
복잡한 통계, 확률 대신 패키지 중심으로 R 배우기
데이터 과학 분야가 성장하며 R 생태계도 풍성해지고 있다. R스튜디오는 GUI 기능이 강화되었고, 멀티 스레드를 지원하는 MRO가 널리 퍼졌으며, AWS 등 클라우드에서 R을 이용하고 나아가 반응형 웹 앱을 만드는 것도 간단해졌다.
이 책은 단순히 R 언어를 익히고 기초적인 분석 방법만을 익히는 시중의 책들과 달리, 오늘날 강력해진 R 생태계의 패키지와 도구를 활용하여 실무적인 데이터 분석 능력을 습득할 수 있게 쓰였다. 1부는 데이터가 무엇인지에 대한 개론으로서 데이터 과학자의 역할과 최근 데이터 과학 기술을 소개한다. 2부에서는 R로 데이터를 다루기 위해 알아야 할 데이터 형태와 구조, 그리고 dplyr와 tidyr을 이용한 데이터 핸들링 방법을 정리했다. 3부는 CSV, XML, SQL 등의 데이터를 읽고 기초 및 고급 통계분석을 수행하는 방법과 ggplot2 시각화를 다룬다. 4부는 대중화되고 있는 클라우드를 활용해 분석 환경을 구성하고, 클라우드 환경에서 분석 및 마크다운 보고서 작성을 수행하며, shiny와 plotly로 결과를 실시간으로 확인할 수 있는 반응형 웹 앱을 개발하는 방법도 다룬다.
처음 R 언어를 다루는 초보자는 물론, 실무자에게도 꼭 필요한 노하우를 알차게 담았다. 데이터 분석가나 데이터 과학자라는 직업에 도전하려는 많은 사람에게 도움이 되리라 자부한다.
주요 내용
- 데이터 과학자에게 필요한 역량 숙지하기
- R스튜디오 설치하고 R 기초 문법 익히기
- 행과 열 전환, 추출, 선택, 조합 등 데이터 조작
- CSV, XLS, JSON, SQL 등에서 데이터 읽기
- 회귀분석, 의사결정나무, 랜덤 포레스트 등 통계분석과 시각화
- AWS, 애저 등 클라우드 분석 환경 구성 및 활용
오탈자 등록