오늘날 대중적인 웹 서비스라면 아무것도 저장하지 않고 운영되는 경우를 거의 찾기 어렵습니다. 쇼핑몰 사이트는 상품과 회원 정보를 저장해야 하고, 학교 사이트는 학과와 학생, 교수 정보 등을 저장해야 하죠. 정보를 올바르게 관리하지 못하면 서비스에 큰 타격을 받을 수 있습니다.
데이터베이스와 데이터베이스 관리 체계인 DBMS가 무엇인지, 왜 파일에 저장하지 않고 DBMS를 이용하는지, 데이터베이스를 이해하기 위해 필요한 기본 용어에는 어떤 것들이 있는지 정리하면서 데이터베이스에 대한 큰 그림을 그려 보겠습니다.
데이터베이스database의 사전적 정의는 ‘여러 사람이 공유하여 사용할 목적으로 체계화해 통합, 관리하는 데이터의 집합’입니다. 즉, 데이터베이스란 원하는 기능을 동작시키기 위해 마땅히 저장해야 하는 정보의 집합을 말합니다.
어떤 데이터가 저장되는지에 따라 웹 서비스의 정체성이 달라질 수 있고, 데이터가 저장되는 방식에 따라 웹 서비스의 성능이 달라집니다. 데이터베이스를 제대로 관리하기 위한 수단이 데이터베이스 관리 시스템(이하 DBMS)Database Management System입니다. DBMS에는 아주 다양한 종류가 있습니다.
DBMS는 크게 두 유형으로 구분할 수 있습니다. 관계형 데이터베이스 관리 시스템(이하 RDBMS 혹은 관계형 데이터베이스)Relational DataBase Management System과 NoSQL 데이터베이스 관리 시스템(이하 NoSQL DBMS, 혹은 NoSQL 데이터베이스)입니다. 대표적인 RDBMS로는 MySQL, Oracle, PostgreSQL, SQLite, MariaDB, Microsoft SQL Server 등이 있으며, NoSQL DBMS에는 MongoDB, Redis 등이 있습니다.
이 중 집중해서 알아둘 DBMS는 무엇일까요? 다음은 2023년 약 6만 명의 전문 개발자를 대상으로 진행한 설문조사의 결과입니다. 답변 결과를 살펴보면 PostgreSQL의 점유율(49.09%)이 가장 높은 것으로 보이지만, 7위로 꼽힌 MariaDB(17.69%)는 2위 MySQL(40.59%)의 오픈소스 버전에 해당하므로 점유율이 가장 높은 RDBMS는 사실상 MySQL입니다.

[출처] https://survey.stackoverflow.co/2023/#most-popular-technologies-platform
DBMS는 여느 응용 프로그램과 다를 바 없는 응용 프로그램입니다. 다만, DBMS는 사용자와 직접적으로 상호작용하기보다는 사용자(개발자)가 만든 프로그램과 상호작용하며 실행됩니다.

응용 프로그램(들)의 입장에서 바라본 DBMS는 마치 서버와 같습니다. 응용 프로그램이 DBMS를 이용하는 과정은 클라이언트-서버 간의 동작과 유사합니다. 주로 쓰리 웨이 핸드셰이크를 통한 TCP 연결을 맺으며, 때로는 데이터베이스에 접속하기 위한 인증이 필요하기도 합니다.
네트워크에서 클라이언트가 서버에 요청을 보내듯, DBMS 클라이언트는 DBMS에 쿼리query를 보냅니다. 이를 위해 DBMS는 데이터베이스를 다루기 위한 언어(데이터베이스 언어)를 제공합니다. 사용자/응용 프로그램은 DBMS의 데이터베이스 언어를 통해 데이터베이스를 다룰 수 있게 되는 셈입니다.
대표적인 데이터베이스 언어인 SQLStructured Query Language은 RDBMS에서 데이터를 조작하고 관리하기 위한 언어로, 이름 그대로 데이터베이스에 질의(Query)하기 위한 구조화된(Structured) 언어(Language)를 말합니다.

SQL은 크게 네 종류로 분류됩니다. 데이터 정의를 위한 DDLData Definition Language과 데이터 조작을 위한 DMLData Manipulation Language, 데이터 제어를 위한 DCLData Control Language, 트랜잭션을 제어하기 위한 TCLTransaction Control Language입니다.
| 종류 | 명령 | 설명 |
| DDL | CREATE | 데이터베이스 혹은 테이블, 뷰, 인덱스 등의 데이터베이스 객체 생성 |
| ALTER | 데이터베이스 객체 갱신 | |
| DROP | 데이터베이스 객체 삭제 | |
| TRUNCATE | 테이블 구조를 유지한 채 모든 레코드 삭제 | |
| DML | SELECT | 테이블의 레코드 조회 |
| INSERT | 테이블의 레코드 삽입 | |
| UPDATE | 테이블의 레코드 갱신 | |
| DELETE | 테이블의 레코드 삭제 | |
| DCL | COMMIT | 데이터베이스에 작업 반영 |
| ROLLBACK | 작업 이전의 상태로 되돌림 | |
| SAVEPOINT | 롤백의 기준점 설정 | |
| TCL | SAVEPOINT | 사용자에게 권한 부여 |
| REVOKE | 사용자로부터 권한 회수 |
운영체제의 파일 시스템을 활용하면 데이터를 파일과 디렉터리의 형태로 관리할 수 있습니다. 왜 파일 시스템 대신 데이터베이스를 이용하는 것일까요? 가령 학과와 학생에 대한 데이터를 다음과 같은 ‘학과.txt’와 ‘학생.txt’ 파일에 저장해서 관리하면 안 될까요? 이 질문에 대한 답은 DBMS가 제공하는 주요 기능과 직결됩니다.

데이터를 단순 나열하여 파일에 저장할 경우의 단점, 곧 한계점이 이 질문에 대한 답변이 될 것입니다. 여러 가지 이유를 찾을 수 있겠지만, 대표적으로 다음 5가지 이유를 추려 보았습니다.
➊ 데이터 일관성 및 무결성 제공이 어렵습니다.
데이터베이스를 한 명의 사용자 혹은 하나의 프로그램만 이용하는 경우는 거의 없습니다. 보통 여러 명의 사용자, 프로그램이 동시다발적으로 데이터베이스를 이용합니다. 레이스 컨디션 문제가 발생할 여지가 있고, 이로 인해 데이터의 일관성이 훼손되기가 쉽습니다.
다시 말해, 데이터의 무결성을 보장하기가 어렵습니다. 위의 ‘학생.txt’ 파일 내용을 다시 한번 봐주세요. ‘이영희’라는 학생의 나이가 잘못된 값 ‘-1’로 저장되어 있지만, 모든 데이터를 파일을 기반으로 저장 할 경우 이러한 잘못된 값을 검출하기가 어렵습니다.
➋ 불필요한 중복 저장이 많아집니다.
다량의 데이터 관리에 있어 불필요한 중복 저장은 스노우볼이 되어 큰 저장 공간 낭비로 이어질 수 있습니다. 파일로 다량의 데이터를 관리할 경우, 불필요한 중복 저장이 발생하기가 쉽습니다. ‘학과.txt’와 ‘학생.txt’ 파일에서 ‘학과 이름=’과 ‘학과 코드=, 학생=, 이름=, 사는 곳=, 학과=, 학번=’은 모두 굳이 중복 저장할 필요가 없는 정보입니다. 또 ‘학과.txt’의 ‘학생=’은 ‘학생.txt’의 ‘학생=’ 데이터와 중복된 저장이죠.
➌ 데이터 변경 시 연관 데이터 변경이 어렵습니다.
가령 ‘학과.txt’의 ‘학과 이름’이 ‘컴퓨터과학’에서 ‘컴퓨터학과’로 변경되었다고 가정해 보세요. ‘학생.txt’ 파일에서 학과가 ‘컴퓨터과학’인 모든 학생의 학과 이름을 일일이 변경해야 할 것입니다. 또 만약 ‘강민철’이라는 학생이 컴퓨터과학과에서 경제학과로 전과한 경우를 가정해 보면 다음과 같이 ‘학과.txt’의 두 곳, ‘학생.txt’의 한 곳을 하나 하나 변경해야 합니다.

➍ 정교한 검색이 어렵습니다.
파일에서도 데이터 검색은 가능하지만, 많은 경우 파일 내 문자열 검색에 국한되는 경우가 많습니다. 가령 ‘나이가 25살 이상인 컴퓨터과학과인 서울 거주자’라는 식의 정교한 검색의 경우 파일만으로는 어렵습니다.
➎ 백업 및 복구가 어렵습니다.
앞서 언급했듯 데이터베이스는 보통 여러 명의 사용자 및 프로그램이 동시다발적으로 이용하기 때문에 많은 데이터베이스에서 백업과 복구 기능을 제공합니다. 하지만 단순 파일 입출력에서는 이러한 기능을 애초에 제공하지 않거나 데이터베이스에 비해 부족한 수준으로 지원합니다. 이와 같은 이유로 다량의 데이터를 바탕으로 많은 사용자 및 프로그램에 제공해야 하는 경우, 단순 파일 입출력보다 데이터베이스가 효율적일 수 있습니다.
데이터베이스 학습을 시작하려면 데이터베이스에 무엇이 어떻게 저장되는지, 데이터베이스의 연산에는 어떤 성질이 있는지 이해해야 합니다. 이와 관련해 데이터베이스의 저장 단위인 엔티티와 스키마, 트랜잭션에 대해 알아보겠습니다.
데이터베이스에는 다양한 속성을 가진 독립적 객체들이 저장될 수 있습니다. 이때 ‘독립적으로 존재할 수 있는 객체’를 엔티티entity라고 하는데요. ‘어떠한 특성을 가진 대상’이라고 할 수 있다면 모두 엔티티라고 볼 수 있습니다. 예를 들어 다음과 같은 그림 속 하나 하나의 대상이 모두 데이터베이스에 저장 가능한 엔티티인 셈입니다.
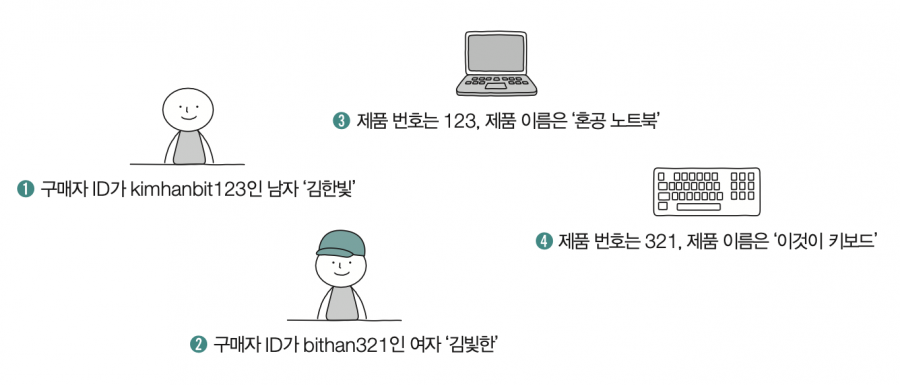
속성attribute은 엔티티의 특성을 의미합니다. 제시된 그림에서 구매자 ID, 구매자의 이름과 성별, 제품 번호와 이름이 바로 각 엔티티의 속성입니다. 각각의 엔티티는 속성을 강조하여 다음과 같이 표기할 수 있습니다.
➊ 구매자 ID 속성=123, 구매자 이름 속성=‘김한빛’, 구매자 성별 속성=남자
➋ 구매자 ID 속성 = 321, 구매자 이름 속성 = ‘김빛한’, 구매자 성별 속성 = 여자
➌ 제품 번호 속성 = abc123, 제품 이름 속성 = ‘혼공 노트북’
➍ 제품 번호 속성 = def321, 제품 이름 속성 = ‘이것이 키보드’
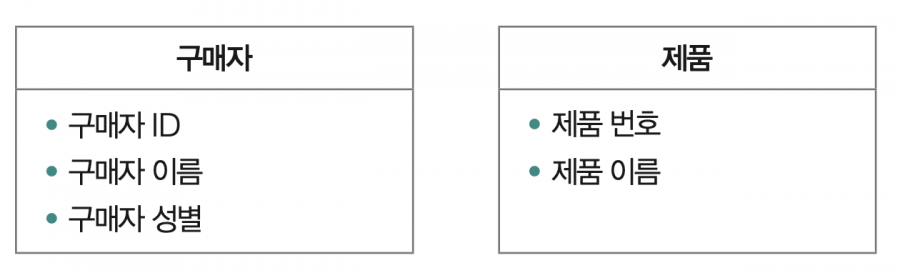
이때 같은 속성을 공유하는 개별 엔티티는 같은 엔티티 집합에 속한다고 할 수 있습니다. 예컨대 ➊과 ➋는 엔티티 ‘구매자’라는 엔티티 집합으로 표현할 수 있고, ➌과 ➍는 ‘제품’이라는 엔티티 집합으로 표현할 수 있습니다. 즉, 데이터베이스 내에 엔티티 집합이 정의될 수 있고, 엔티티 집합에 속한 다 양한 개별 엔티티들이 저장될 수 있습니다.
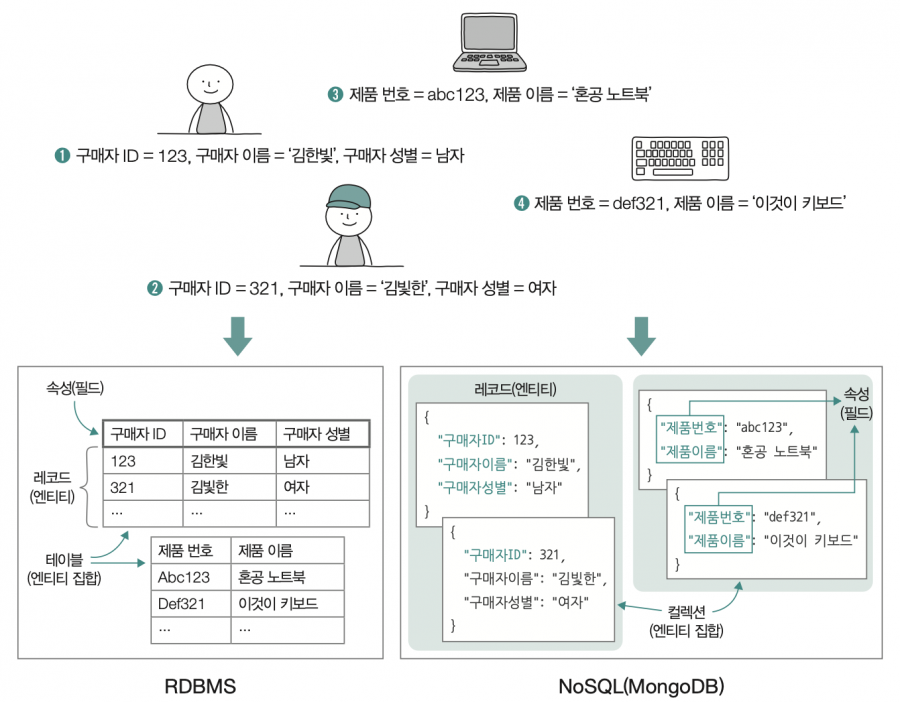
DBMS마다 다양하게 엔티티 집합을 표현할 수 있는데, RDBMS는 엔티티 집합을 테이블(표)의 형태로 표현하며 릴레이션relation이라고도 부릅니다. 또 NoSQL DBMS의 일종인 MongoDB에서는 엔티티 집합을 컬렉션collection이라는 단위로 표현합니다. 다양한 엔티티들이 RDBMS에서는 테이블 안에, MongoDB에서는 컬렉션 안에 저장되는 것 입니다.
엔티티를 데이터베이스에 ‘저장 가능한 대상’이라고 한다면, 레코드는 데이터베이스에 ‘저장된 대상’ 이라고 할 수 있습니다. 데이터베이스에 ‘기록’된 각각의 엔티티를 레코드record라고 부르는 셈입니다. 데이터베이스에 저장된 엔티티 속성은 필드field라고 합니다. 즉, 다양한 속성을 지닌 엔티티들이 다양한 필드를 지닌 레코드로써 데이터베이스에 저장될 수 있습니다.
RDBMS에서는 개별 레코드를 테이블의 행으로 표현하고, 필드를 테이블의 열로 표현합니다. 또한 NoSQL DBMS인 MongoDB에서는 개별 레코드를 Json 형태의 데이터인 도큐먼트document라는 단위로 표현하고, 필드를 Json 키의 형태로 표현합니다.
RDBMS와 NoSQL을 구분하는 주요 기준 중 하나로 스키마의 유무를 꼽을 수 있습니다. 스키마schema 는 데이터베이스에 저장되는 레코드의 구조와 제약 조건을 정의한 것으로, 레코드가 지켜야 할 틀이자 청사진이라고 볼 수 있습니다.
데이터베이스에 저장되는 개별 레코드를 달고나라고 생각하고, 스키마를 달고나의 틀이라고 생각해 보세요. 스키마가 명확히 정의되어 있다면, 즉 달고나 틀이 있다면 틀(스키마)에 맞는 반듯한 모양의 달고나(정형화된 데이터)를 저장하고 관리하기가 용이할 것입니다. 반면, 명확히 따라야 할 스키마가 없다면, 즉 달고나 틀이 없다면 자유롭게 다양한 형태의 달고나를 만들 수 있듯 유연한 형태 의 데이터를 저장하고 관리하기가 용이합니다.
앞서 RDBMS에서는 레코드를 테이블 내행으로 저장하고, NoSQL의 일종인 MongoDB에서는 컬렉션 내 도큐먼트로 저장한다고 했습니다. 따라서 RDBMS에서는 명확한 스키마가 정의되며, 레코드들은 이 스키마로 정해진 테이블의 구조, 필드의 데이터 타입 및 제약 조건을 따라야 합니다. 다음과 같은 ‘학생’ 테이블이 있다고 가정해 보세요. 이 테이블의 구조와 각 필드의 데이터 타입, 제약 조건 등이 정의된 틀이 바로 스키마입니다.
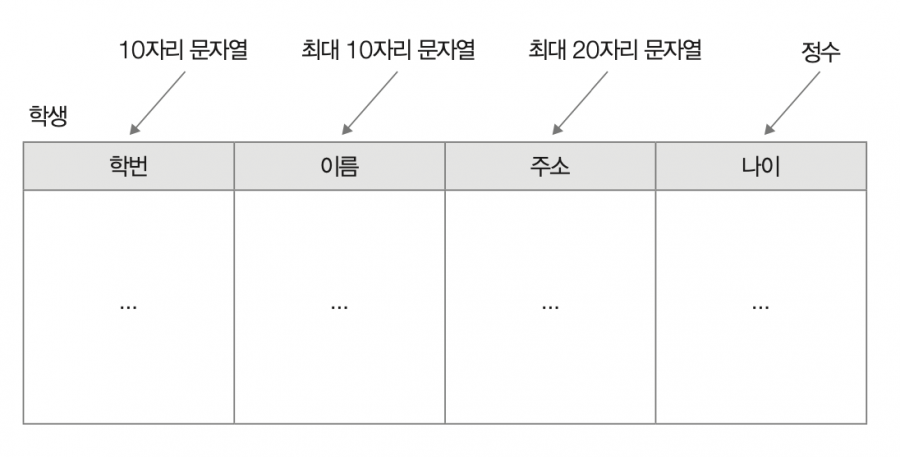
반면, NoSQL에서는 명확한 스키마가 정의되지 않기 때문에 NoSQL 데이터베이스를 스키마-리스schema-less 데이터베이스라고도 부릅니다. 레코드들이 지켜야 할 구조와 제약 조건에 제한이 없어 RDBMS보다 자유로운 형태의 레코드를 저장할 수 있습니다. MongoDB에 ‘학생’이라는 컬렉션이 있다고 가정했을 때 이 컬렉션에는 다음과 같은 2개의 도큐먼트가 저장될 수 있습니다.
첫 번째 도큐먼트
{
"name": "hanbit",
"age": 30,
"email": "hanbit@example.com"
}
두 번째 도큐먼트
{
"name": "media",
"age": 25,
"email": "media@example.com",
"address": {
"street": "123 Main St",
"city": "Somewhere",
"zipcode": "12345"
}
}
정형화된 데이터만 저장 가능한 RDBMS와는 다르게, 고정된 스키마를 따르지 않아 더욱 유연한 형태로 레코드를 관리할 수 있겠죠.
트랜잭션transaction은 데이터베이스와의 논리적 상호작용의 단위를 의미합니다. 데이터베이스가 처리하는 작업의 단위를 나타내므로 초당 트랜잭션TPS, Transactions Per Second이라는 지표로 데이터베이스의 작업 성능을 나타내기도 합니다. 유의할 점은 트랜잭션이 하나의 쿼리만 포함하는 것은 아니라는 점입니다. 예를 들어 ‘한빛’이가 ‘빛한’이에게 5,000원을 이체하는 트랜잭션에서는 다음과 같은 2개 이상의 쿼리가 포함될 수 있습니다.
여러 작업을 내포하는 트랜잭션이 동시다발적으로 실행될 때는 안전한 트랜잭션을 보장하기 위해 지켜야 하는 성질이 있습니다. 트랜잭션이 지켜야 하는 성질에는 크게 4가지가 있습니다. 원자성, 일관성, 격리성, 지속성의 앞글자를 따서 ACID라고 하는데요. 데이터베이스, 특히 관계형 데이터베이스 트랜잭션의 상징과도 같은 단어입니다.
➊ 원자성
원자성Atomicity이란 하나의 트랜잭션 결과가 모두 성공하거나 모두 실패하는 성질을 의미합니다. 가령 앞선 예시에서 빛한이의 계좌 잔액을 5,000원 증가시키는 작업이 실행되는 도중 DBMS가 다운되었다면 한빛이의 계좌 잔액을 5,000원 감소시켰던 작업도 취소되어야 합니다. 이렇게 트랜잭션이 하나의 단위로 처리되는 것을 원자성이라고 합니다.
원자성을 상징하는 말로 All or Nothing을 들기도 합니다. 말 그대로, 주어진 작업을 모두 성공하거 나 모두 실패할 뿐, 일부 성공이나 일부 실패는 허용하지 않는다는 의미입니다.
➋ 일관성
트랜잭션 전후로 데이터베이스가 일관된 상태를 유지하는 성질을 일관성Consistency이라고 합니다. 여기서 ‘일관된 상태’란 데이터베이스가 지켜야 하는 일련의 규칙들을 지키는 상태를 의미합니다. 이러한 규칙(일관성)을 깨뜨리지 않는 데이터를 유지하는 성질이 바로 데이터베이스의 일관성입니다. 유의할 점은 데이터베이스가 트랜잭션 이후 다음과 같이 새로운 일관된 상태로 전이될 수 있다는 것 입니다. 다만, 이 경우에도 저장된 데이터들은 모두 일관된 상태를 유지해야 합니다.
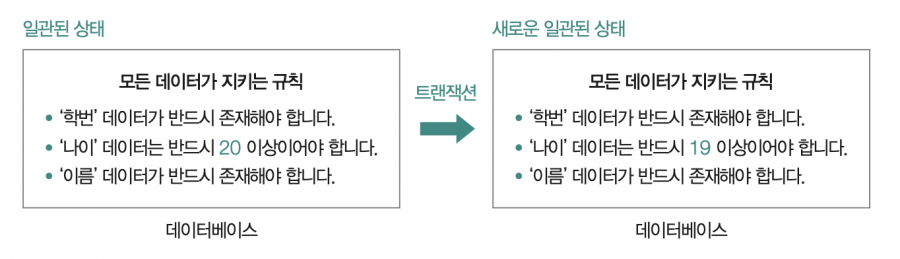
➌ 격리성
격리성Isolation이란 동시에 수행되는 여러 트랜잭션이 서로 간섭하지 않도록 보장하는 성질을 의미합니다. 레이스 컨디션을 방지하기 위한 성질이죠. 즉, 한 트랜잭션이 어떤 데이터에 접근하여 조작 중일 때는 다른 트랜잭션이 접근할 수 없습니다. 예를 들어 재고가 하나뿐인 상품을 두 명의 사용자가 동시에 구매하려고 시도했을 때 격리성이 보장되지 않았다면 두 트랜잭션이 동시에 재고를 확인하고, 각자 재고가 있다고 판단하여 결제를 시도하게 되므로 결국 최종적으로는 재고 부족 문제가 발생할 수 있습니다. 하지만 격리성이 보장된다면 동시에 두 트랜잭션이 수행되지 않으므로 이러한 문제를 방지할 수 있습니다.
➍ 지속성
지속성Durability이란 트랜잭션이 성공적으로 완료된 후에 그 결과가 영구적으로 반영되는 성질을 의미합 니다. 즉, 시스템 장애가 발생하더라도 완료된 트랜잭션의 결과는 손실되지 않아야 합니다. 예를 들어 은행에서 특정 계좌에 돈을 입금하는 트랜잭션이 성공적으로 완료되었다면, 그 결과가 디스크에 기록되어 시스템 장애가 발생하더라도 입금 내역이 사라지지 않아야 합니다. 오늘날 DBMS에는 대부분 이를 보장하기 위한 회복 메커니즘이 구현되어 있습니다.
위 컨텐츠는 『이것이 취업을 위한 컴퓨터 과학이다 with CS 기술 면접』의 내용을 재구성하여 작성되었습니다.

관련 콘텐츠

최신 콘텐츠
![[개발자 CS 기술 면접] 1. 컴퓨터 구조 편(1/5)](/data/cms/CMS2153054762_thumb.png)
![[개발자 CS 기술 면접] 2. 운영체제 편(2/5)](/data/cms/CMS2956113027_thumb.png)
![[개발자 CS 기술 면접] 3. 자료구조 편(3/5)](/data/cms/CMS5987351259_thumb.png)
![[개발자 CS 기술 면접] 4. 네트워크 편(4/5)](/data/cms/CMS9544942055_thumb.png)