IT/모바일
제공 : 한빛 네트워크
저자 : Gilad Buzi, Kelley Glenn, Jonathan Novich
역자 : 백기선
원문 : Agile Database Refactoring with Hibernate
여러분의 애플리케이션을 처음 작성했을 때 데이터 모델은 거의 완벽했을 것입니다. 그 후로 계속 진화하고 있습니다. 데이터 모델이 엉망이 되고 역 정규화 되고 그 결과 회의를 할 때 그것들을 고쳐야 한다는 것에 열을 올려 설명해야 하는 수많은 시간을 소비하고 있습니다.
하지만 여러분은 불안해 합니다. 설득력 있는 언급에도 불구하고 “모든 데이터를 한번에 고치는 일”을 실천에 옮기기 꺼림칙합니다. 너무 위험합니다. 수많은 애플리케이션들이 해당 데이터베이스에 읽고 쓰기 작업을 하고 있습니다. 모든 것들을 한 번에 고칠 수 없습니다! 만약 한 번에 하나씩 데이터 모델을 수정할 수 있거나 한 번에 하나의 애플리케이션을 수정할 수 있다면 어떨까요.
정말 일반적인 경우에 다음과 같을 것입니다. 시간이 갈수록 IT 조직의 크기가 중소 기업이든, 대규모 기업이든 중앙 집중화된 데이터베이스에 저장되어 있는 중요한 데이터에 접근하는 별도의 애플리케이션을 만듭니다. 그리고 적당히 좋지 않게 설계된 데이터 모델은 성능과 확장성(scalability) 그리고 조직의 전반적인 효율성을 서서히 저하시키기 시작합니다.
이 기사에서는 현재 사용하고 있는 애플리케이션이나 프로세스에 영향을 주지 않고 결점이 있는 스키마와 데이터 모델을 수정하는 방법을 보여줄 것입니다. 하이버네이트(버전 3.0이상)에 있는 최신 기술(과 함께 데이터베이스 뷰, 스토어드 프로시저(stored procedure), 표준 디자인패턴)을 사용하면 애플리케이션 개발자와 데이터 아키텍처는 결함이 있는 데이터 모델을 한 번에 한 조각씩 수정할 수 있습니다.
수행 순서
앞으로 다음의 순서대로 할 것입니다.
예제는 전반적으로 역정규화된 주문 시스템입니다. 기존의 데이터 설계자는 주문을 ORDER 테이블과 ORDER_ITEM 테이블로 나누지 않고 모든 주문 데이터를 CUST_ORDER라는 하나의 테이블에 넣기로 결정했습니다. 우리는 이 테이블을 둘로 나누고 싶습니다. 하지만 어떻게 할까요?
[그림 1]은 원래의 설계를 보여주고 있습니다.
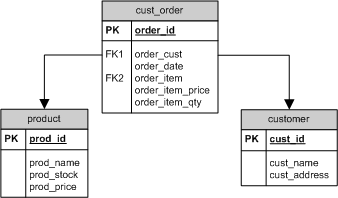
[그림 1] DMA 솔루션을 적용하기 전의 데이터 모델
오케이. 자 이제 고쳐봅시다.
개선된 데이터 모델 생각하기
우리는 이 테이블을 아주 간단하게 쪼갤 수 있다고 결정했습니다. [그림 2]에 보이는 것과 비슷하게 할 수 있습니다.
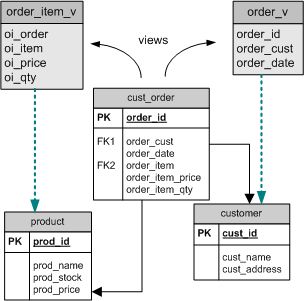
[그림 2] 전반적으로 설계를 개선시키는 뷰를 포함한 데이터 모델
주문 데이터를 두 테이블로 나누면 데이터 중복을 피할 수 있고 보다 견고한 데이터 모델을 유지할 수 있습니다. 하지만 현재의 구조에서 어떻게 그러한 모델로 다다를 수 있을까요?
의사소통이 핵심입니다. 코딩과 테스트 할 것이 거의 없다 하더라도 가장 중요한 요소입니다. 모든 관련된 이해관계자들(stakeholder)이 여러분의 새로운 설계를 설명할 때 참석하도록 하세요. 이해관계자들이란 이 데이터에 접근하는 다른 애플리케이션을 구현하고 있는 개발자, 새로운 데이터 모델을 유지보수 할 데이터베이스 관리자 그리고 마지막으로 데이터 모델이 어떻게 변해야 하는지 각자의 생각을 가지고 있을만한 기술 관리자와 기술 비즈니스 분석가를 말합니다. 의사소통의 중요성은 아무리 강조해도 지나치지 않습니다.
데이터베이스 뷰 만들기
우리가 원하는 구조를 이루기 위해서 전반적으로 역정규화되어 있는 테이블을 사용하고 있는 기존의 스키마에서 데이터베이스 뷰를 정의합니다. 당연히 이 뷰는 정규화 되어 있는 상태로 데이터를 보여주겠죠. ORDER_V 뷰는 CUST_ORDER 테이블을 그룹화 하고 간추린 버전입니다. (구체적인 주문 아이템 정보를 제거하고 그것들을 order_id로 묶었습니다.) 다음과 같이 뷰를 정의했습니다.
스토어드 프로시저 또는 INSTEAD OF 트리거
이제 이 새로운 뷰들을 테이블처럼, 즉 핵심 컨텐츠들을 뒤에서 어떤 일이 벌어지든 신경 쓰지 않고 추가(Create), 수정(Update), 삭제(Delete)하고 싶습니다. 비록 몇몇 뷰들은 데이터베이스 설계 부서에 별도의 개입 없이 직접 수정을 할 수도 있겠지만 예제의 뷰는 약간 복잡합니다. 그리고 우리는 실제 데이터베이스 내부의 (CUST_ORDER) 테이블이 어떻게 영향을 받을지 확실히 알고 싶습니다. 최선의 방법은 뷰에 CUD 오퍼레이션을 수행하려고 할 때마다 실행할 코드를 데이터베이스에 정의하는 것입니다.
대부분의 데이터베이스(MS SQL Server, Sybase, Oracle, DB2)는 INSTEAD OF 트리거를(PostreSQL 은 비슷한 역할을 하는 “rules”를 사용한다.) 사용할 수 있습니다. 이것을 사용하여 뷰의 기본이 되는 테이블에 레코드를 추가, 수정, 삭제할 수 있습니다. 하지만 MySQL은 현재 INSTEAD OF 트리거를 지원하고 있지 않습니다. 대체제로 스토어드 프로시저를 만들 수 있으며 하이버네이트 맵핑 파일을 사용하여 이러한 스토어드 프로시저를 매번 CUD 오퍼레이션이 코드(와 하이버네이트에 의해 영속화되는 것)에 의해 트리거 될 때 마다 호출하도록 할 수 있습니다. 스토어드 프로시저 또는 Instead of 트리거의 코드는 매우 비슷합니다.
예제에서는 MySQL을 사용할 것이기 때문에 스토어드 프로시저를 사용하는 해결책을 선택했습니다.
코드
스토어드 프로시저로 역정규화 테이블에 추가, 수정, 삭제 작업을 할 때 반드시 역정규화의 모든 현상(반복되는 줄, 추가적인 필드, 불필요한 값 등)들을 고려해야 합니다. 이러한 스토어드 프로시저를 사용하면 위에서 정의한 잘 정규화된 뷰로 작성한 데이터 모델을 결함이 있고, 역정규화된 구조로 변환해줘야 합니다. 왜냐고요? 다른 애플리케이션들이 그런 구조의 데이터를 사용하고 있기 때문입니다. 게다가 우리가 작성한 뷰 정의도 기존 구조의 데이터에 의존하고 있습니다.
그럼 프로시저는 어떤 모습을 하고 있을까요? 다음에 주문 아이템을 추가하는 예제가 있습니다.
 역자 백기선님은 AJN(http://agilejava.net)에서 자바 관련 스터디를 하고 있는 착하고 조용하며 점잖은 대학생입니다.
요즘은 특히 Spring과 Hibernate 같은 오픈소스 프레임워크를 공부하고 있습니다. 공부한 내용들은 블로그(http://whiteship.tistory.com)에 간단하게 정리하고 있으며 장래 희망은 행복한 개발자입니다.
역자 백기선님은 AJN(http://agilejava.net)에서 자바 관련 스터디를 하고 있는 착하고 조용하며 점잖은 대학생입니다.
요즘은 특히 Spring과 Hibernate 같은 오픈소스 프레임워크를 공부하고 있습니다. 공부한 내용들은 블로그(http://whiteship.tistory.com)에 간단하게 정리하고 있으며 장래 희망은 행복한 개발자입니다.
저자 : Gilad Buzi, Kelley Glenn, Jonathan Novich
역자 : 백기선
원문 : Agile Database Refactoring with Hibernate
여러분의 애플리케이션을 처음 작성했을 때 데이터 모델은 거의 완벽했을 것입니다. 그 후로 계속 진화하고 있습니다. 데이터 모델이 엉망이 되고 역 정규화 되고 그 결과 회의를 할 때 그것들을 고쳐야 한다는 것에 열을 올려 설명해야 하는 수많은 시간을 소비하고 있습니다.
하지만 여러분은 불안해 합니다. 설득력 있는 언급에도 불구하고 “모든 데이터를 한번에 고치는 일”을 실천에 옮기기 꺼림칙합니다. 너무 위험합니다. 수많은 애플리케이션들이 해당 데이터베이스에 읽고 쓰기 작업을 하고 있습니다. 모든 것들을 한 번에 고칠 수 없습니다! 만약 한 번에 하나씩 데이터 모델을 수정할 수 있거나 한 번에 하나의 애플리케이션을 수정할 수 있다면 어떨까요.
정말 일반적인 경우에 다음과 같을 것입니다. 시간이 갈수록 IT 조직의 크기가 중소 기업이든, 대규모 기업이든 중앙 집중화된 데이터베이스에 저장되어 있는 중요한 데이터에 접근하는 별도의 애플리케이션을 만듭니다. 그리고 적당히 좋지 않게 설계된 데이터 모델은 성능과 확장성(scalability) 그리고 조직의 전반적인 효율성을 서서히 저하시키기 시작합니다.
이 기사에서는 현재 사용하고 있는 애플리케이션이나 프로세스에 영향을 주지 않고 결점이 있는 스키마와 데이터 모델을 수정하는 방법을 보여줄 것입니다. 하이버네이트(버전 3.0이상)에 있는 최신 기술(과 함께 데이터베이스 뷰, 스토어드 프로시저(stored procedure), 표준 디자인패턴)을 사용하면 애플리케이션 개발자와 데이터 아키텍처는 결함이 있는 데이터 모델을 한 번에 한 조각씩 수정할 수 있습니다.
수행 순서
앞으로 다음의 순서대로 할 것입니다.
- 개선된 데이터 모델 생각하기.: 현재 모델의 잘못된 점이 무엇인지 파악하고 어떻게 수정할지 결정합니다.
- 데이터베이스 뷰 만들기: 현재 (결함이 있는)모델에 비하여 이러한 뷰들은 여러분이 원하는 데이터 모델을 반영합니다.
- 스토어드 프로시저 또는 ‘instead of’ 트리거 만들기: 이것들이 기본 테이블에 대한 변경을 대체할 것입니다.
- POJO, 하이버네이트 맵핑, DAO를 개발: 새로운 데이터 모델을 표현하고 앞에서 작성한 뷰와 연결합니다.
- 테스트, 테스트, 테스트: 데이터 모델이 정확한지 증명합니다.
예제는 전반적으로 역정규화된 주문 시스템입니다. 기존의 데이터 설계자는 주문을 ORDER 테이블과 ORDER_ITEM 테이블로 나누지 않고 모든 주문 데이터를 CUST_ORDER라는 하나의 테이블에 넣기로 결정했습니다. 우리는 이 테이블을 둘로 나누고 싶습니다. 하지만 어떻게 할까요?
[그림 1]은 원래의 설계를 보여주고 있습니다.
[그림 1] DMA 솔루션을 적용하기 전의 데이터 모델
오케이. 자 이제 고쳐봅시다.
개선된 데이터 모델 생각하기
우리는 이 테이블을 아주 간단하게 쪼갤 수 있다고 결정했습니다. [그림 2]에 보이는 것과 비슷하게 할 수 있습니다.
[그림 2] 전반적으로 설계를 개선시키는 뷰를 포함한 데이터 모델
주문 데이터를 두 테이블로 나누면 데이터 중복을 피할 수 있고 보다 견고한 데이터 모델을 유지할 수 있습니다. 하지만 현재의 구조에서 어떻게 그러한 모델로 다다를 수 있을까요?
의사소통이 핵심입니다. 코딩과 테스트 할 것이 거의 없다 하더라도 가장 중요한 요소입니다. 모든 관련된 이해관계자들(stakeholder)이 여러분의 새로운 설계를 설명할 때 참석하도록 하세요. 이해관계자들이란 이 데이터에 접근하는 다른 애플리케이션을 구현하고 있는 개발자, 새로운 데이터 모델을 유지보수 할 데이터베이스 관리자 그리고 마지막으로 데이터 모델이 어떻게 변해야 하는지 각자의 생각을 가지고 있을만한 기술 관리자와 기술 비즈니스 분석가를 말합니다. 의사소통의 중요성은 아무리 강조해도 지나치지 않습니다.
데이터베이스 뷰 만들기
우리가 원하는 구조를 이루기 위해서 전반적으로 역정규화되어 있는 테이블을 사용하고 있는 기존의 스키마에서 데이터베이스 뷰를 정의합니다. 당연히 이 뷰는 정규화 되어 있는 상태로 데이터를 보여주겠죠. ORDER_V 뷰는 CUST_ORDER 테이블을 그룹화 하고 간추린 버전입니다. (구체적인 주문 아이템 정보를 제거하고 그것들을 order_id로 묶었습니다.) 다음과 같이 뷰를 정의했습니다.
CREATE VIEW dma_example.order_v
AS select
dma_example.cust_order.order_id AS order_id,
dma_example.cust_order.order_cust AS order_cust,
max(dma_example.cust_order.order_date) AS order_date
from dma_example.cust_order
group by dma_example.cust_order.order_id;
ORDER_ITEM_V 뷰는 오직 주문 아이템에 대한 상세 정보만을 담고 있으며 고객의 id와 (ORDER_V 뷰에서 포착할 수 있는)데이터는 제외했습니다. 다음과 같이 ORDER_ITEM_V 를 정의했습니다.
CREATE VIEW dma_example.order_item_v
AS select
dma_example.cust_order.order_id AS oi_order,
dma_example.cust_order.order_item AS oi_item,
dma_example.cust_order.order_item_price AS oi_price,
dma_example.cust_order.order_item_qty AS oi_qty
from dma_example.cust_order
where (dma_example.cust_order.order_item is not null);
지금까지 기본적으로 하나의 테이블을 둘로 나눴습니다.
스토어드 프로시저 또는 INSTEAD OF 트리거
이제 이 새로운 뷰들을 테이블처럼, 즉 핵심 컨텐츠들을 뒤에서 어떤 일이 벌어지든 신경 쓰지 않고 추가(Create), 수정(Update), 삭제(Delete)하고 싶습니다. 비록 몇몇 뷰들은 데이터베이스 설계 부서에 별도의 개입 없이 직접 수정을 할 수도 있겠지만 예제의 뷰는 약간 복잡합니다. 그리고 우리는 실제 데이터베이스 내부의 (CUST_ORDER) 테이블이 어떻게 영향을 받을지 확실히 알고 싶습니다. 최선의 방법은 뷰에 CUD 오퍼레이션을 수행하려고 할 때마다 실행할 코드를 데이터베이스에 정의하는 것입니다.
대부분의 데이터베이스(MS SQL Server, Sybase, Oracle, DB2)는 INSTEAD OF 트리거를(PostreSQL 은 비슷한 역할을 하는 “rules”를 사용한다.) 사용할 수 있습니다. 이것을 사용하여 뷰의 기본이 되는 테이블에 레코드를 추가, 수정, 삭제할 수 있습니다. 하지만 MySQL은 현재 INSTEAD OF 트리거를 지원하고 있지 않습니다. 대체제로 스토어드 프로시저를 만들 수 있으며 하이버네이트 맵핑 파일을 사용하여 이러한 스토어드 프로시저를 매번 CUD 오퍼레이션이 코드(와 하이버네이트에 의해 영속화되는 것)에 의해 트리거 될 때 마다 호출하도록 할 수 있습니다. 스토어드 프로시저 또는 Instead of 트리거의 코드는 매우 비슷합니다.
예제에서는 MySQL을 사용할 것이기 때문에 스토어드 프로시저를 사용하는 해결책을 선택했습니다.
코드
스토어드 프로시저로 역정규화 테이블에 추가, 수정, 삭제 작업을 할 때 반드시 역정규화의 모든 현상(반복되는 줄, 추가적인 필드, 불필요한 값 등)들을 고려해야 합니다. 이러한 스토어드 프로시저를 사용하면 위에서 정의한 잘 정규화된 뷰로 작성한 데이터 모델을 결함이 있고, 역정규화된 구조로 변환해줘야 합니다. 왜냐고요? 다른 애플리케이션들이 그런 구조의 데이터를 사용하고 있기 때문입니다. 게다가 우리가 작성한 뷰 정의도 기존 구조의 데이터에 의존하고 있습니다.
그럼 프로시저는 어떤 모습을 하고 있을까요? 다음에 주문 아이템을 추가하는 예제가 있습니다.
create procedure insert_order_item
(in itemprice FLOAT, in itemqty INT, in orderid INT, in itemid INT)
LANGUAGE SQL
BEGIN
DECLARE p_order_id INT;
DECLARE p_cust_id INT;
DECLARE max_order_id INT;
DECLARE p_itemprice FLOAT;
-- apply the current price to the line item
if itemprice is null then
select prod_price into p_itemprice from product where prod_id=itemid;
else
set p_itemprice = itemprice;
end if;
-- get the customer id.
select order_cust into p_cust_id
from cust_order where order_id=orderid limit 1;
insert into cust_order
(order_id, order_cust, order_date,
order_item, order_item_price, order_item_qty)
values
(orderid, p_cust_id, now(), itemid, p_itemprice, itemqty);
END
ORDER_ITEM_V 뷰에서 어떤 데이터를 제외시켰든지 상관없이 모든 데이터를 CUST_ORDER 테이블에 추가해야 합니다. 이 프로시저가 CUST_ORDER 테이블에 추가하는 작업을 성공적으로 완료하면 영향을 받는 row의 숫자인 1을 반환할 것입니다. 각각을 테이블(실제로는 뷰이지만)에서 스토어드 프로시저들을 하나의 row로 취급하기 때문에 하이버네이트가 스토어드 프로시저의 결과로 1또는 0을 기대하고 있다는 것을 아는 것이 중요합니다. 실제 그런지 확인하기 위해 스토어드 프로시저를 가지고 작은 실험을 해볼 수 있습니다. 예를 들어, 하나의 주문 아이템을 업데이트 하기 위한 스토어드 프로시저가 CUST_ORDER 테이블의 여러 row(모든 주문 아이템에서 한 개의 row)에 영향을 끼칠 수 있을 것입니다. 만약 주어진 주문 ID를 가지고 있는 모든 row를 수정하려고 한다면 값이 바뀐 row의 수가 1보다 크게 됩니다. 이렇게 하면 하이버네이트에서 문제를 발생시키기 때문에 작은 테이블을 사용하고 CUST_ORDER 테이블을 수정한 다음에 갱신할 것입니다. 이렇게 하면 스토어드 프로시저가 영향을 받은 row의 숫자로 1을 반환합니다. (예상한 수정이 오직 하나의 row에만 변화를 주었기 때문에) 다음에 수정하는 스토어드 프로시저를 확인할 수 있습니다.
create procedure update_order
(in ordercust INT, in orderdate DATETIME, in orderid INT)
LANGUAGE SQL
BEGIN
update cust_order set order_cust=ordercust,
order_date=orderdate
where order_id=orderid;
if row_count() > 0 then
update help_table set i=i+1;
end if;
END
역자 백기선님은 AJN(http://agilejava.net)에서 자바 관련 스터디를 하고 있는 착하고 조용하며 점잖은 대학생입니다.
요즘은 특히 Spring과 Hibernate 같은 오픈소스 프레임워크를 공부하고 있습니다. 공부한 내용들은 블로그(http://whiteship.tistory.com)에 간단하게 정리하고 있으며 장래 희망은 행복한 개발자입니다. TAG :

최신 콘텐츠